
2023-04-10 at 19:00:00
March 10th, 2023 marked my 15th year contributing to Mozilla as a volunteer. In this blog post I will focus on the past 5 years. Before reading this, you might want to check out my previous blog post about my first 10 years.
Unfortunately I can't provide the same level of granular statistics as I did in that blog post, as the data aggregation from back then does not exist anymore. However, I created my own tool to track my contributions and you can find all my contributions listed in the Open Source section of this website. I might write about that tool in the future, until then you can set this up for yourself as well. The code can be found on GitHub.
Most of this blog post will focus on Common Voice, as that is the main project I have worked on in the past 5 years. This is the story of how I got to contribute to it and what contributions I've made over the years. Many of these efforts were based on input and collaboration of the community!
Common Voice is Mozilla's effort to create a public domain dataset of voice recordings that can be used to create Machine Learning models to recognize speech. For more information check out the About page on Common Voice.
As part of my Mozilla Reps work, I helped organize the Mozilla Berlin presence of Mozilla's Global Sprint in May 2018. The Global Sprint was a global event encouraging participants to create fun projects for a healthy internet. For the Berlin instance of this event we decided to focus on Common Voice. One benefit of this was that the Common Voice team was located in Berlin and therefore easily could help us out. At that point I had heard about Common Voice before, but I do not remember contributing to it before this event.
At the event we used a localization tool to submit and review sentences, as that already had a review flow. These sentences then get shown to the voice contributors to record. To get a good dataset many hours of recorded speech is necessary. Many hours of speech also means many sentences that need to be available to be recorded. As you might imagine, this does not scale well. Later that year in July Mike Henretty committed the first version of the Sentence Collector to GitHub. This then allowed as to improve upon and create a flow that specifically fits the purpose and processes of Common Voice.
My first commit to the Sentence Collector repository was in November 2018. Since then I have maintained and improved the Sentence Collector as a volunteer. There were contributions from time to time from other contributors and of course the whole thing would not have been possible without the discussions with the community.
The initial version looked slightly different, but at some point I decided to get it a bit closer to the design of the Common Voice website. This is how it looks now:
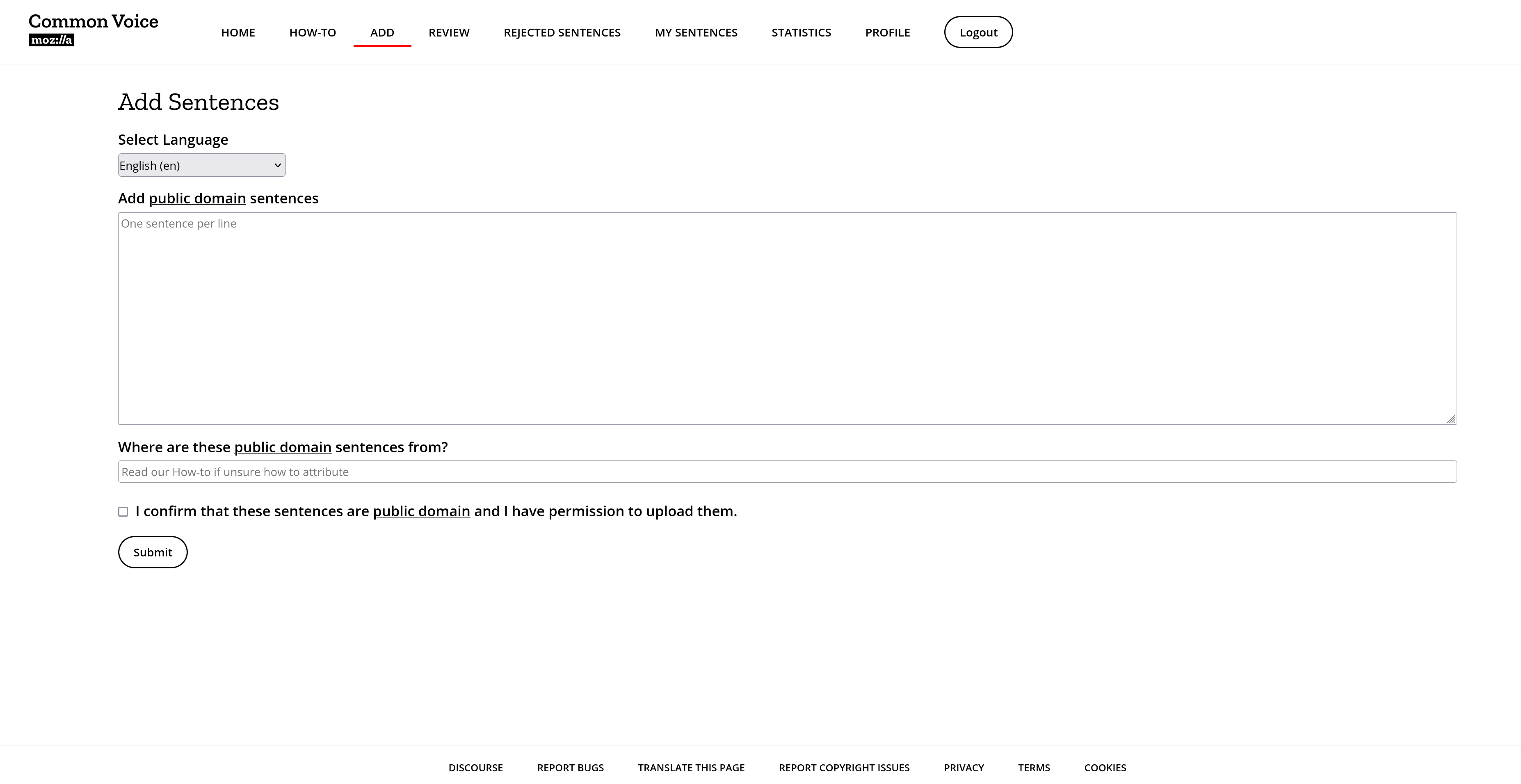
For some time in the beginning Sentence Collector did not have a real backend. The frontend basically directly contacted Kinto, which worked out quite well initially. However with time our requirements became more complex and we had to switch to using a real backend. I fully developed this backend based on a Node. This was quite a project to do in my free time, as there was no existing backend and therefore also no deployment processes. Additionally at that point we decided to introduce the same login mechanism as Common Voice uses and therefore we also had to integrate with Auth0, which made the whole project even bigger. However this was a great learning opportunity for me, as I had never worked with OAuth before that.
Currently there is an ongoing project to fully integrate the Sentence Collector into the Common Voice platform. Until now it was quite hard to find the Sentence Collector and its code was completely independent of the Common Voice platform. This required us to come up with some processes to get the data integrated and keep everything consistent. We had talked about this more than 2 years ago, but it simply never happened. Therefore I'm very happy that this is now happening.
As one-off contributions submitting sentences through Sentence Collector was not enough for all languages, the Common Voice team also created a tool that extracts sentences from Wikipedia (with legal requirements applied). That tool is called Sentence Extractor. Around June 2019 I started contributing to that tool as well and then later on took over maintenance as well. Since then I helped integrate more sources apart from just Wikipedia, as well as creating more rules that can be applied to find the right sentences to extract. All of these rules are documented in the README file.
A bigger project for the Sentence Extractor was the automation of the extraction process. For a long time trusted contributors ran the extraction process locally on their machine and then uploaded the resulting sentences file to the Common Voice repository. This could take hours to run. I created a GitHub Actions workflow which automates the process, while also making sure that none of the sentences changed. This allows anyone to trigger an extract and then the only manual process is to submit a PR with the file to the Common Voice repository. However the content of that file is easily comparable to the output of the GitHub Action and therefore guarantees compliance with the legal requirements easily.
After moving to Berlin at the beginning of 2018 I started helping out with organizing community events in the Mozilla office. I joined the already existing bi-weekly Mozilla Nights and helped mentor attendees and then also further on helped organize those events. Unfortuantely we did not switch those bi-weekly Mozilla Nights to be online events and had to pause them during the pandemic.
We have also organized campaign specific events between 2018 and the beginning of 2020, whenever Mozilla had a global campaign that benefited from having physical events happening. You can find previous campaigns as well as upcoming campaigns on the Community Portal. For many of those campaigns we needed a bug reporting form, therefore I develop and keep maintaining the campaign-form which gets adjusted of reach campaign.
I have also continued to be a Peer for the Reps program. However admittedly, in the past 2 years I did not contribute as much to the Reps program. If you'd like to chat with me about the program, I'm super happy to do so though!
And finally, I organized the virtual Mozilla presence in the Mozilla Dev Room at FOSDEM 2022 together with other volunteers.
I have also continued to write some patches for Firefox. These usually come in batches of 2 or 3 at the tiem and then I don't contribute to Firefox code for another half year. You can find a list of my fixed bugs on Bugzilla. I'm probably going to keep contributing to Firefox from time to time, however I do not have a big amount of time availabe these days.